Lulus kuliah kini jenjang yang pembelaharan di tahap strata awal sudah dilalui dengan baik. Tahap selanjutnya diharapkan dapat melanjutkan ke jenjang berikutnya atau menghadapi kenyataan dunia. Pilihan pun jatuh untuk menghadapi kenyataan hidup untuk turut serta ambil bagian bersaing mencari penghasilan.
Dunia baru sudah ada di depan mata hampir tiap detik bersaing dengan waktu mencari kesempatan dan peluang yang diciptakan oleh beberapa orang.
DISTRIBUTED PROCESSING
DISTRIBUTED PROCESSING
a. Artikel tentang Komputasi dan Tentang Parallel Processing
Komputasi dan Parallel Processing Komputasi
Setiap jenis perhitungan atau penggunaan teknologi komputer dalam pengolahan informasi. Perhitungan adalah proses setelah yang jelas model yang dipahami dan dinyatakan dalam suatu algoritma , protokol , topologi jaringan , dll Perhitungan juga merupakan subyek utama dari ilmu komputer : menyelidiki apa yang dapat atau tidak dapat dilakukan dengan cara komputasi.
Perhitungan dapat diklasifikasikan oleh setidaknya tiga kriteria ortogonal: digital vs analog , sekuensial vs paralel vs bersamaan , bets vs interaktif .
Dalam prakteknya, perhitungan digital sering digunakan untuk mensimulasikan proses alam (misalnya, perhitungan Evolusi ), termasuk yang lebih alami dijelaskan oleh model analog perhitungan (misalnya, jaringan syaraf tiruan ).
Parallel Processing
Dalam komputer, pemrosesan paralel merupakan pengolahan dari Program instruksi dengan membagi mereka di antara beberapa prosesor dengan tujuan untuk menjalankan program dalam waktu kurang. Dalam komputer paling awal, hanya satu program berlari pada suatu waktu. Sebuah program komputasi- intensif yang memakan waktu satu jam untuk menjalankan dan menyalin Program tape yang mengambil satu jam untuk menjalankan akan mengambil total dua jam untuk menjalankan. Bentuk awal dari pemrosesan paralel memungkinkan eksekusi interleaved kedua program bersama-sama. Komputer akan memulai operasi I / O, dan sementara itu sedang menunggu operasi untuk menyelesaikan, itu akan mengeksekusi program prosesor-intensif. Waktu eksekusi total untuk dua pekerjaan akan menjadi sedikit lebih dari satu jam.
Peningkatan berikutnya multiprogramming . Dalam sistem multiprogramming, beberapa program telah dikirim pengguna yang masing-masing diperbolehkan untuk menggunakan prosesor untuk waktu yang singkat. Untuk pengguna tampak bahwa semua program yang melaksanakan pada saat yang sama. Masalah pertama muncul pertentangan sumber daya di sistem ini. Permintaan eksplisit untuk sumber daya menyebabkan masalah dari kebuntuan . Kompetisi untuk sumber daya pada mesin tanpa dasi-melanggar instruksi mengarah pada rutin critical section .
Langkah berikutnya dalam pengolahan paralel adalah pengenalan multiprocessing . Dalam sistem ini, dua atau lebih prosesor berbagi pekerjaan yang akan dilakukan. Versi awal memiliki master / slave konfigurasi. Salah satu prosesor (master) diprogram untuk bertanggung jawab atas semua pekerjaan dalam sistem, yang lain (budak) dilakukan hanya tugas-tugas itu diberikan oleh master. Pengaturan ini diperlukan karena tidak kemudian mengerti bagaimana program mesin sehingga mereka bisa bekerja sama dalam pengelolaan sumber daya sistem.
Hubungan antara komputasi modern dengan paralel processing
Kinerja komputasi dengan menggunakan paralel processing itu menggunakan dan memanfaatkan beberapa komputer atau CPU untuk menemukan suatu pemecahan masalah dari masalah yang ada. Sehingga dapat diselesaikan dengan cepat daripada menggunakan satu komputer saja. Komputasi dengan paralel processing akan menggabungkan beberapa CPU, dan membagi-bagi tugas untuk masing-masing CPU tersebut. Jadi, satu masalah terbagi-bagi penyelesaiannya. Tetapi ini untuk masalah yang besar saja, komputasi yang masalah kecil, lebih murah menggunakan satu CPU saja.
Sumber :
http://shara9128.blogspot.com/2012/03/komputasi-dan-parallel -processing.html http://3anapoe3.wordpress.com/2013/06/10/komputasi-dan-parallel-processing/
Konsep komputasi Parallel Processing
Paralel Processing adalah kemampuan menjalankan tugas atau aplikasi lebih dari satu aplikasi dan dijalankan secara simultan atau bersamaan pada sebuah komputer. Secara umum, ini adalah sebuah teknik dimana sebuah masalah dibagi dalam beberapa masalah kecil untuk mempercepat proses penyelesaian masalah.
Terdapat dua hukum yang berlaku dalam sebuah parallel processing. yaitu:
- Hukum Amdahl
Amdahl berpendapat, “Peningkatan kecepatan secara paralel akan menjadi linear, melipatgandakan kemampuan proses sebuah komputer dan mengurangi separuh dari waktu proses yang diperlukan untuk menyelesaikan sebuah masalah.”
- Hukum Gustafson
Pendapat yang dikemukakan Gustafson hampir sama dengan Amdahl, tetapi dalam pemikiran Gustafson, sebuah komputasi paralel berjalan dengan menggunakan dua atau lebih mesin untuk mempercepat penyelesaian masalah dengan memperhatikan faktor eksternal, seperti kemampuan mesin dan kecepatan proses tiap-tiap mesin yang digunakan.

Distribusi Parallel Processing
Gambar diatas merupakan contoh dari sebuah komputasi paralel, dimana pada gambar diatas terdapat sebuah masalah, dari masalah tersebut dibagi lagi menjadi beberapa bagian agar sebuah masalah dapat dengan cepat diatasi.
Tujuan Komputasi Paralel
Tujuan dari komputasi paralel adalah meningkatkan kinerja komputer dalam menyelesaikan berbagai masalah. Dengan membagi sebuah masalah besar ke dalam beberapa masalah kecil, membuat kinerja menjadi cepat.
Formula komputasi paralel yang diajukan pada hukum Amdahl
s=1/a
Dimana a adalah banyaknya paralel yang terjadi. Secara teori, artinya proses penyelesaian masalah menjadi lebih cepat dengan menggunakan komputasi paralel.
Salah satu jenis penggunaan komputasi paralel adalah:
PVM(Parallel Virtual Machine)
Merupakan sebuah perangkat lunak yang mampu mensimulasikan pemrosesan paralel pada jaringan. Model komputasi Paralel.
- Embarasingly Paralleladalah pemrograman paralel yang digunakan pada masalah-masalah yang bisa diparalelkan tanpa membutuhkan komunikasi satu sama lain. Sebenarnya pemrograman ini bisa dibilang sebagai pemrograman paralel yang ideal, karena tanpa biaya komunikasi, lebih banyak peningkatan kecepatan yang bisa dicapai.
- Taksonomi dari model pemrosesan paralel dibuat berdasarkan alur instruksi dan alur data yang digunakan:
– SISD (Single Instruction Single Datapath) merupakan prosesor tunggal, yang bukan paralel.
– SIMD (Single Instruction Multiple Datapath)alur instruksi yang sama dijalankan terhadap banyak alur data yang berbeda. Alur instruksi di sini kalau tidak salah maksudnya ya program komputer itu. trus datapath itu paling ya inputnya, jadi inputnya lain-lain tapi program yang digunakan sama.
– MIMD (Multiple Instruction Multiple Datapath)alur instruksinya banyak, alur datanya juga banyak, tapi masing-masing bisa berinteraksi.
– MISD (Multiple Instruction Single Datapath)alur instruksinya banyak tapi beroperasi pada data yang sama.
Perbedaan komputasi tunggal dan komputasi parallel dapat digambarkan sebagai berikut

komputasi tunggal
Komputasi Parallel
Kesimpulannya :
- Pengolahan Parallel adalah pengolahan informasi yang menekankan pada manipulasi data-data elemen secara simultan.
- Pengolahan Parallel dimaksudkan untuk mempercepat komputasi dari sistem computer dan menambah jumlah keluaran yang dapat dihasilkan dalam jangka waktu tertentu.
- Pengolahan Parallel merupakan pengolahan informasi yang ditekankan pada manipulasi elemen data yang dimiliki oleh satu atau lebih dari satu proses secara bersamaan dalam rangka menyelesaikan sebuah problem.
Sumber :
http://andri102.wordpress.com/game/soft-skill/konsep-komputasi-parallel-processing/
http://3anapoe3.wordpress.com/2013/06/10/komputasi-dan-parallel-processing/
http://nindyastuti52.wordpress.com/2011/03/22/kinerja-komputasi-dengan-parallel-processing/
apa itu big data
Apa itu Big Data?
Nama :Muhammad Rizki
Kelas : 4IA17
NPM : 54410806
Latar belakang
Akhir-akhir ini, istilah ‘big data’ menjadi topik yang dominan dan sangat sering dibahas dalam industri IT. Banyak pihak yang mungkin heran kenapa topik ini baru menjadi pusat perhatian padahal ledakan informasi telah terjadi secara berkelangsungan sejak dimulainya era informasi. Perkembangan volume dan jenis data yang terus meningkat secara berlipat-lipat dalam dunia maya Internet semenjak kelahirannya adalah fakta yang tak dapat dipungkiri. Mulai data yang hanya berupa teks, gambar atau foto, lalu data berupa video hingga data yang berasal system pengindraan. Lalu kenapa baru sekarang orang ramai-ramai membahas istilah big data? Apa sebenarnya ‘big data’ itu?
Hingga saat ini, definisi resmi dari istilah big data belum ada. Namun demikian, latar belakang dari munculnya istilah ini adalah fakta yang menunjukkan bahwa pertumbuhan data yang terus berlipat ganda dari waktu ke waktu telah melampaui batas kemampuan media penyimpanan maupun sistem database yang ada saat ini. Kemudian, McKinseyGlobal Institute (MGI), dalam laporannya yang dirilis pada Mei 2011, mendefinisikan bahwa big data adalah data yang sudah sangat sulit untuk dikoleksi, disimpan, dikelola maupun dianalisa dengan menggunakan sistem database biasa karena volumenya yang terus berlipat. Tentu saja definisi ini masih sangat relatif, tidak mendeskripsikan secara eksplisit sebesar apa big data itu. Tetapi, untuk saat sekarang ini, data dengan volume puluhan terabyte hingga beberapa petabyte kelihatannya dapat memenuhi definis MGI tersebut. Di lain pihak, berdasarkan definisi dari Gartner, big data itu memiliki tiga atribute yaitu : volume , variety , dan velocity. Ketiga atribute ini dipakai juga oleh IBM dalam mendifinisikan big data. Volume berkaitan dengan ukuran, dalam hal ini kurang lebih sama dengan definisi dari MGI. Sedangkan variety berarti tipe atau jenis data, yang meliputi berbagai jenis data baik data yang telah terstruktur dalam suatu database maupun data yang tidak terorganisir dalam suatu database seperti halnya data teks pada web pages, data suara, video, click stream, log file dan lain sebagainya. Yang terakhir, velocity dapat diartikan sebagai kecepatan dihasilkannya suatu data dan seberapa cepat data itu harus diproses agar dapat memenuhi permintaan pengguna.
Pembahasan
Definisi Big Data
Jika diterjemahkan secara mentah-mentah maka Big Data berarti suatu data dengan kapasitas yang besar. Sebagai contoh, saat ini kapasitas DWH yang digunakan oleh perusahaan-perusahaan di Jepang berkisar dalam skala terabyte. Namun, jika misalnya dalam suatu sistem terdapat 1000 terabyte (1 petabyte) data, apakah sistem tersebut bisa disebut Big Data?
Satu lagi, Big Data sering dikaitkan dengan SNS (Social Network Service), contohnya Facebook. Memang benar Facebook memiliki lebih dari 800 juta orang anggota, dan dikatakan bahwa dalam satu hari Facebook memproses sekitar 10 terabyte data. Pada umumnya, SNS seperti Facebook tidak menggunakan RDBMS(Relational DataBase Management System) sebagai software pengolah data, melainkan lebih banyak menggunakan NoSQL. Lalu, apa kita bisa menyebut sistem NoSQL sebagaiBig Data?
Dengan mengkombinasikan kedua uraian diatas, dapat ditarik sebuah definisi bahwa Big Data adalah “suatu sistem yang menggunakan NoSQL dalam memproses atau mengolah data yang berukuran sangat besar, misalnya dalam skala petabyte“. Apakah definisi ini tepat? Boleh dikatakan masih setengah benar. Definisi tersebut masih belum menggambarkan Big Data secara menyeluruh. Big Datatidak sesederhana itu,
Big Data memuat arti yang lebih kompleks sehingga perlu definisi yang sedikit lebih kompleks pula demi mendeskripsikannya secara keseluruhan.
Mengapa butuh definisi yang lebih kompleks? Fakta menunjukkan bahwa bukan hanya NoSQL saja yang mampu mengolah data dalam skala raksasa (petabyte). Beberapa perusahaan telah menggunakan RDBMS untuk memberdayakan data dalam kapasitas yang sangat besar. Sebagai contoh, Bank of America memiliki DWH dengan kapasitas lebih dari 1,5 petabyte, Wallmart Stores yang bergerak dalam bisnis retail (supermarket) berskala dunia telah mengelola data berkapasitas lebih dari 2,5 petabyte, dan bahkan situs auction (lelang) eBay memiliki DWH yang menyimpan lebih dari 6petabyte data. Oleh karena itu, hanya karena telah berskala petabyte saja, suatu data belum bisa disebut Big Data. Sekedar referensi, DWH dengan kapasitas sangat besar seperti beberapa contoh diatas disebut EDW(Enterprise Data Warehouse) dan database yang digunakannya disebut VLDB(Very Large Database).
Memang benar, NoSQL dikenal memiliki potensi dan kapabilitas Scale Up (peningkatan kemampuan mengolah data dengan menambah jumlah server atau storage) yang lebih unggul daripada RDBMS. Tetapi, bukan berarti RDBMS tak diperlukan. NoSQL memang lebih tepat untuk mengolah data yang sifatnya tak berstruktur seperti data teks dan gambar, namun NoSQL kurang tepat bila digunakan untuk mengolah data yang sifatnya berstruktur seperti data-data numerik, juga kurang sesuai untuk memproses data secara lebih detail demi menghasilkan akurasi yang tinggi. Pada kenyataannya, Facebook juga tak hanya menggunakan NoSQL untuk memproses data-datanya, Facebook juga tetap menggunakan RDBMS. Lain kata, penggunaan RDBMS dan NoSQL mesti disesuaikan dengan jenis data yang hendak diproses dan proses macam apa yang dibutuhkan guna mendapat hasil yang optimal.
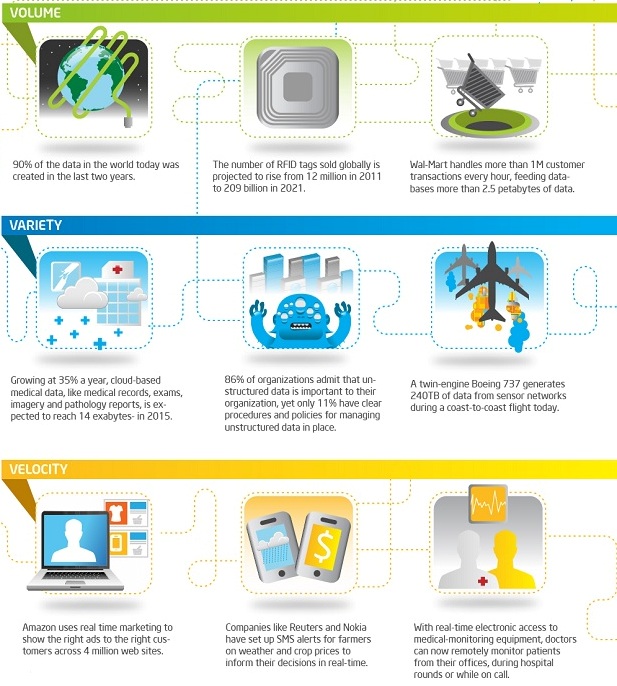
Gambar Big Data Infographic sumber intel.co.jp
Karakteristik Big Data : Volume, Variety, Velocity (3V)
Kembali ke pertanyaan awal, apakah sebenarnya Big Data itu? Sayang sekali, hingga saat ini masih belum ada definisi baku yang disepakati secara umum. Ada yang mendeskripsikan Big Data sebagai fenomena yang lahir dari meluasnya penggunaan internet dan kemajuan teknologi informasi yang diikuti dengan terjadinya pertumbuhan data yang luar biasa cepat, yang dikenal dengan istilah ledakan informasi (Information Explosion) maupun banjir data (Data Deluge). Hal ini mengakibatkan terbentuknya aliran data yang super besar dan terus-menerus sehingga sangat sulit untuk dikelola, diproses, maupun dianalisa dengan menggunakan teknologi pengolahan data yang selama ini digunakan (RDBMS). Definisi ini dipertegas lagi dengan menyebutkan bahwa Big Data memiliki tiga karakteristik yang dikenal dengan istilah 3V: Volume, Variety, Velocity. Dalam hal ini, Volumemenggambarkan ukuran yang superbesar, Variety menggambarkan jenis yang sangat beragam, danVelocity menggambarkan laju pertumbuhan maupun perubahannya. Namun demikian, definisi ini tentu masih sulit untuk dipahami. Oleh karena itu, uraian berikut mencoba memberikan gambaran yang lebih jelas dan nyata berkaitan dengan maksud definisi Big Data tersebut.

Gambar karakteristik big data
Bukan Hanya Masalah Ukuran, Tapi Lebih pada Ragam
Kini jelas bahwa Big Data bukan hanya masalah ukuran yang besar, terlebih yang menjadi ciri khasnya adalah jenis datanya yang sangat beragam dan laju pertumbuhan maupun frekwensi perubahannya yang tinggi. Dalam hal ragam data, Big Data tidak hanya terdiri dari data berstruktur seperti halnya data angka-angka maupun deretan huruf-huruf yang berasal dari sistem database mendasar seperti halnya sistem database keuangan, tetapi juga terdiri atas data multimedia seperti data teks, data suara dan video yang dikenal dengan istilah data tak berstruktur. Terlebih lagi, Big Data juga mencakup data setengah berstruktur seperti halnya data e-mail maupun XML. Dalam hal kecepatan pertumbuhan maupun frekwensi perubahannya, Big Data mencakup data-data yang berasal dari berbagai jenis sensor, mesin-mesin, maupun data log komunikasi yang terus menerus mengalir. Bahkan, juga mencakup data-data yang tak hanya data yang berada di internal perusahaan, tetapi juga data-data di luar perusahaan seperti data-data di Internet. Begitu beragamnya jenis data yang dicakup dalam Big Data inilah yang kiranya dapat dijadikan patokan untuk membedakan Big Data dengan sistem manajemen data pada umumnya.
Fokus pada Trend per-Individu, Kecepatan Lebih Utama daripada Ketepatan
Hingga saat ini, pendayagunaan Big Data didominasi oleh perusahaan-perusahaan jasa berbasis Internet seperti halnya Google dan Facebook. Data yang mereka berdayakan pun bukanlah data-data internal perusahaan seperti halnya data-data penjualan maupun data pelanggan, lebih menitik beratkan pada pengolahan data-data teks dan gambar yang berada di Internet. Bila kita melihat gaya pemberdayaan data yang dilakukan oleh perusahaan-perusahaan pada umumnya, yang dicari adalahtrend yang didapat dari pengolahan data secara keseluruhan. Misalnya, dari data konsumen akan didapat informasi tentang trend konsumen dengan memproses data konsumen secara keseluruhan, bukan memproses data per-konsumen untuk mendapatkan trend per-konsumen. Dilain pihak, perusahaan-perusahaan jasa berbasis Internet yang memanfaatkan Big Data justru memfokuskan pemberdayaan data untuk mendapatkan informasi trend per-konsumen dengan memanfaatkan atribut-atribut yang melekat pada pribadi tiap konsumen. Sebut saja toko online Amazon yang memanfaatkan informasi maupun atribut yang melekat pada diri per-konsumen, untuk memberikan rekomendasi yang sesuai kepada tiap konsumen. Satu lagi, pemberdayaan data ala Big Data ini dapat dikatakan lebih berfokus pada kecepatan ketimbang ketepatan.
MapReduce
MapReduce adalah model pemrograman rilisan Google yang ditujukan untuk memproses data berukuran raksasa secara terdistribusi dan paralel dalam cluster yang terdiri atas ribuan komputer. Dalam memproses data, secara garis besar MapReduce dapat dibagi dalam dua proses yaitu proses Map dan proses Reduce. Kedua jenis proses ini didistribusikan atau dibagi-bagikan ke setiap komputer dalam suatu cluster (kelompok komputer yang salih terhubung) dan berjalan secara paralel tanpa saling bergantung satu dengan yang lainnya. Proses Map bertugas untuk mengumpulkan informasi dari potongan-potongan data yang terdistribusi dalam tiap komputer dalam cluster. Hasilnya diserahkan kepada proses Reduce untuk diproses lebih lanjut. Hasil proses Reduce merupakan hasil akhir yang dikirim ke pengguna.
Dari definisinya, MapReduce mungkin terkesan sangat ribet. Untuk memproses sebuah data raksasa, data itu harus dipotong-potong kemudian dibagi-bagikan ke tiap komputer dalam suatu cluster. Lalu proses Map dan proses Reduce pun harus dibagi-bagikan ke tiap komputer dan dijalankan secara paralel. Terus hasil akhirnya juga disimpan secara terdistribusi. Benar-benar terkesan merepotkan.
Beruntunglah, MapReduce telah didesain sangat sederhana alias simple. Untuk menggunakan MapReduce, seorang programer cukup membuat dua program yaitu program yang memuat kalkulasi atau prosedur yang akan dilakukan oleh proses Map dan Reduce. Jadi tidak perlu pusing memikirkan bagaimana memotong-motong data untuk dibagi-bagikan kepada tiap komputer, dan memprosesnya secara paralel kemudian mengumpulkannya kembali. Semua proses ini akan dikerjakan secara otomatis oleh MapReduce yang dijalankan diatas Google File System

Gambar map and reduce Google file service
Program yang memuat kalkulasi yang akan dilakukan dalam proses Map disebut Fungsi Map, dan yang memuat kalkulasi yang akan dikerjakan oleh proses Reduce disebut Fungsi Reduce. Jadi, seorang programmer yang akan menjalankan MapReduce harus membuat program Fungsi Map dan Fungsi Reduce. Fungsi Map bertugas untuk membaca input dalam bentuk pasangan Key/Value, lalu menghasilkan output berupa pasangan Key/Value juga. Pasangan Key/Value hasil fungsi Map ini disebut pasangan Key/Value intermediate. Kemudian, fungsi Reduce akan membaca pasangan Key/Value intermediate hasil fungsi Map, dan menggabungkan atau mengelompokkannya berdasarkan Key tersebut. Lain katanya, tiap Value yang memiliki Key yang sama akan digabungkan dalam satu kelompok. Fungsi Reduce juga menghasilkan output berupa pasangan Key/Value. Untuk memperdalam pemahaman, mari kita simak satu contoh. Taruhlah kita akan membuat program MapReduce untuk menghitung jumlah tiap kata dalam beberapa file teks yang berukuran besar.Dalam program ini, fungsi Map dan fungsi Reduce dapat didefinisikan sebagai berikut:
map(String key, String value):
//key : nama file teks.
//value: isi file teks tersebut.
for each word W in value:
emitIntermediate(W,”1″);
reduce(String key, Iterator values):
//key : sebuah kata.
//values : daftar yang berisi hasil hitungan.
int result = 0;
for each v in values:
result+=ParseInt(v);
emit(AsString(result));
Hasil akhir dari program ini adalah jumlah dari tiap kata yang terdapat dalam file teks yang dimasukkan sebagai input program ini.
Gambar Menghitung jumlah tiap kata pada dokumen

Dari segi teknologi, dipublikasikannya GoogleBigtable pada 2006 telah menjadi moment muncul dan meluasnya kesadaran akan pentingnya kemampuan untuk memproses ‘big data’. Berbagai layanan yang disediakan Google, yang melibatkan pengolahan data dalam skala besar termasuk search engine-nya, dapat beroperasi secara optimal berkat adanya Bigtable yang merupakan sistem database berskala besar dan cepat. Semenjak itu, teknik akses dan penyimpanan data KVS (Key-Value Store) dan teknik komputasi paralel yang disebutMapReduce mulai menyedot banyak perhatian. Lalu, terinspirasi oleh konsep dalam GoogleFile System dan MapReduce yang menjadi pondasi Google Bigtable, seorang karyawan Yahoo! bernama Doug Cutting kemudian mengembangkan software untuk komputasi paralel terdistribusi (distributed paralel computing) yang ditulis dengan menggunakan Java dan diberi nama Hadoop. Saat ini Hadoop telah menjadi project open source-nyaApache Software. Salah satu pengguna Hadoop adalah Facebook, SNS (Social Network Service) terbesar dunia dengan jumlah pengguna yang mencapai 800 juta lebih. Facebook menggunakan Hadoop dalam memproses big data seperti halnya content sharing, analisa access log, layanan message / pesan dan layanan lainnya yang melibatkan pemrosesan big data.
Kesimpulan
Berdasar uraian diatas, dapat ditarik kesimpulan bahwa yang dimaksud dengan ‘big data’ bukanlah semata-mata hanya soal ukuran, bukan hanya tentang data yang berukuran raksasa. Big data adalah data berukuran raksasa yang volumenya terus bertambah, terdiri dari berbagai jenis atau varietas data, terbentuk secara terus menerus dengan kecepatan tertentu dan harus diproses dengan kecepatan tertentu pula. Momen awal ketenaran istilah ‘big data’ adalah kesuksesan Google dalam memberdayakan ‘big data’ dengan menggunakan teknologi canggihnya yang disebut Bigtable beserta teknologi-teknologi pendukungnya
Daftar Pustaka
http://vijjam.blogspot.com/2013/03/apa-itu-big-data.html
http://vijjam.blogspot.com/2013/12/memahami-definisi-big-data.html
http://vijjam.blogspot.jp/2013/02/mapreduce-besar-dan-powerful-tapi-tidak.html
Distributed Computation dalam Cloud Computing
Distributed Computation dalam Cloud Computing
Nama : Muhammad Rizki
Kelas : 4ia17
NPM : 54410806
- Latar Belakang
Cloud computing adalah model komputasi dimana sumber daya seperti daya komputasi, media penyimpanan, jaringan dan software dijalankan sebagai layanan melalui media jaringan, bahkan dapat diakses di tempat manapun selama terkoneksi dengan internet.
Kelebihan Cloud Computing:
a. Lebih efisien karena menggunakan anggaran rendah untuk resource nya.
b. Dapat berorientasi dengan mudah pada perkembangan yang cepat.
Kekurangan Cloud Computing:
a. Tidak dapat dilakukan jika tidak terhubung ke internet.
b. Jika koneksi internet lambat maka cloud computing tidak optimal digunakan
c. Fitur yang dihadirkan tidak selengkap aplikasi desktop
d.Data yang disimpan dalam awan tidak begitu aman karena diperbanyak dibeberapa mesin.
- Penjelasan
Distributed Computing adalah ilmu yang memecahkan masalah besar dengan memberikan bagian kecil dari masalah untuk banyak komputer untuk memecahkan dan kemudian menggabungkan solusi untuk bagian-bagian menjadi solusi untuk masalah tersebut. Distributed computing terkait dengan system perangkat keras dan perangkat lunak yang memiliki lebih dari satu elemen pemrosesan atau storage element.

Pada cloud computing, penyimpanan data hanya dilakukan pada server utama, sehingga pengguna hanya dapat mengaksesnya tanpa harus mengetahui infrastruktur pembuatan aplikasinya. Hanya perlu interface software saja untuk mengakses server. Interface ini pada umumnya merupakan web browser yang tersedia dengan banyak pilihan dan tidak berbayar.
Cloud computing dipecah ke dalam beberapa kategori yang berbeda berdasarkan jenis layanan yang disediakan. SaaS (Software as a Service) adalah kategori komputasi awan di mana sumber daya utama yang tersedia sebagai layanan perangkat lunak aplikasi. PaaS (Platform as a Service) adalah kategori / penerapan komputasi awan di mana penyedia layanan memberikan platform komputasi atau solusi tumpukan untuk pelanggan mereka melalui internet. IaaS (Infrastructure as a Service) adalah kategori komputasi awan di mana sumber daya utama yang tersedia sebagai layanan yang infrastruktur perangkat keras. DaaS (Desktop sebagai Layanan), yang merupakan layanan muncul-Aas berkaitan dengan memberikan pengalaman seluruh desktop melalui internet. Ini kadang-kadang disebut sebagai virtualisasi desktop / virtual desktop atau desktop host.
Bidang ilmu komputer yang berkaitan dengan sistem terdistribusi disebut komputasi terdistribusi. Sebuah sistem terdistribusi terdiri dari lebih dari satu komputer self-directed berkomunikasi melalui jaringan. Komputer-komputer ini menggunakan memori lokal mereka sendiri. Semua komputer dalam sistem terdistribusi berbicara satu sama lain untuk mencapai tujuan bersama tertentu. Atau, pengguna yang berbeda pada setiap komputer mungkin memiliki kebutuhan individu yang berbeda dan sistem terdistribusi akan melakukan koordinasi sumber daya bersama (atau bantuan berkomunikasi dengan node lain) untuk mencapai tugas-tugas masing-masing. Node berkomunikasi menggunakan message passing. Komputasi terdistribusi juga dapat diidentifikasi sebagai menggunakan sistem terdistribusi untuk memecahkan masalah besar tunggal dengan melanggar itu dengan tugas, masing-masing yang dihitung masing-masing komputer dari sistem terdistribusi. Biasanya, mekanisme toleransi berada di tempat untuk mengatasi kegagalan komputer individu. Struktur (topologi, delay dan kardinalitas) dari sistem ini tidak dikenal di muka dan itu bersifat dinamis. Komputer individu tidak harus tahu segala sesuatu tentang seluruh sistem atau masukan lengkap (untuk masalah yang akan dipecahkan).
- Kesimpulan
Cloud computing adalah teknologi yang memberikan berbagai jenis sumber daya sebagai layanan, terutama melalui internet, sedangkan komputasi terdistribusi adalah konsep menggunakan sistem terdistribusi terdiri dari banyak node diatur sendiri untuk memecahkan masalah yang sangat besar (yang biasanya sulit untuk diselesaikan dengan satu komputer). Cloud computing pada dasarnya adalah penjualan dan model distribusi untuk berbagai jenis sumber daya melalui internet, sedangkan komputasi terdistribusi dapat diidentifikasi sebagai jenis komputasi, yang menggunakan sekelompok mesin untuk bekerja sebagai satu kesatuan untuk memecahkan masalah skala besar. Komputasi terdistribusi mencapai hal ini dengan memecah masalah ke tugas sederhana, dan menugaskan tugas-tugas ke node individu.
Teori Komputasi Modern dan Implementasi di bidang Fisika, Biologi, Matematika, Ekonomi dan Geologi
Teori Komputasi Modern dan Implementasi di bidang Fisika, Biologi, Matematika, Ekonomi dan Geologi
Nama : Muhammad Rizki
Kelas : 4IA17
NPM : 54410806
1.1 Latar belakang
Sebuah komputasi bermula karena tidak ada alat hitung yang dapat menghitung dalam jumlah besar pada zaman dahulu kala, namun seiring perkembangan zaman fungsi dari sebuah komputasi bertambah bukan hanya untuk menghitung namun juga untuk memperagakan simulasi, pemrosesan data yang banyak, membantu manusia dalam membuat keputusan dan lainnya.
1.2 Tujuan
Tujuan dari penulisan ini diharapkan dapat mengetahui bagaimana proses komputasi bermula dan di manfaatkan untuk mempermudah manusia dalam melakukan pekerjaan dibidang apapun.
2.1 Penjelasan Komputasi Modern
Karakteristik komputasi modern ada 3 macam, yaitu :
1. Komputer-komputer penyedia sumber daya bersifat heterogenous karena terdiri dari berbagai jenis perangkat keras, sistem operasi, serta aplikasi yang terpasang.
2. Komputer-komputer terhubung ke jaringan yang luas dengan kapasitas bandwidth yang beragam.
3. Komputer maupun jaringan tidak terdedikasi, bisa hidup atau mati sewaktu-waktu tanpa jadwal yang jelas.
Selanjutnya Menjelaskan Macam-macam Komputasi Modern
Komputasi modern terbagi tiga macam, yaitu komputasi mobile (bergerak), komputasi grid dan komputasi cloud. Penjelasan lebih lanjut dari jenis-jenis komputasi modern sebagai berikut:
Mobile Computing.
Mobile Computing atau komputasi bergerak memiliki beberapa penjelasan, salah satunya komputasi bergerak merupakan kemajuan teknologi komputer sehingga dapat berkomunikasi menggunakan jaringan tanpa kabel dan mudah dibawa atau berpindah tempat, tetapi berbeda dengan komputasi nirkabel. Contoh dari perangkat komputasi bergerak seperti GPS, juga tipe dari komputasi bergerak seperti smartphone dan lain sebagainya.
Grid Computing
Komputasi Grid menggunakan komputer yang terpisah oleh geografis, didistribusikan dan terhubung oleh jaringan untuk menyelesaikan masalah komputasi skala besar. Ada beberapa daftar yang dapat digunakan untuk mengenali sistem komputasi grid, yaitu:
a.Sistem untuk koordinat sumber daya komputasi tidak dibawah kendali pusat.
b.Sistem menggunakan standart dan protocol yang terbuka.
c.Sistem mencoba mencapai kualitas pelayanan yang canggi. yang lebih baik diatas kualitas komponen individe pelayan komputasi grid.
Cloud Computing
Komputasi Cloudmerupakan gaya komputasi yang terukut dinamis dan sumber daya virtual yang sering menyediakan layanan melalui internet. Komputasi Cloud menggambarkan pelengkap baru, konsumsi dan layanan IT berbasi model dalam internet, dan biasanya melibatkan ketentuan dari keterukuran dinamis dan sumber daya virtual yang sering menyediakan layanan melalui internet.
Komputasi modern dapat dimanfaakan untuk memecahkan masalah seperti dibawah ini:
Modeling (NN&GA)
Modeling merupakan suatu hal yang penting dalam melakukan suatu perhitungan yang rumit.
Problem Volume Besar (Down Sizzing atau paralel)
Data yang besar tentu membutuhkan suatu cara penyelesaian yang khusus. Karena data yang besar dapat menjadi masalah jika ada yang terlewatkan. Dengan metode ini data yang besar diparalelkan dalam pengolahan sehingga dapat diorganisir dengan baik.
Akurasi (big, Floating point)
Akurasi dibutuhkan dalam memecahkan masalah. Maka dari itu sebuah komputasi modern digunakan untuk menemukan sebuah jawaban yang akurat.
Kompleksitas
Untuk menangani masalah yang kompleks maka sebuah komputasi diharapkan dapat melakukan perhitungan yang kompleks.
Kecepatan
Masalah diharapkan dapat diselesaikan dengan cepat maka kecepatan menjadi sesuatu yang penting dalam mempersingkat waktu menjawab masalah.
2.2 Implementasi Komputasi Modern pada Bidang Fisika
Implementasi komputasi moderndi bidang fisika ada Computational Physics yang mempelajari suatu gabungan antara Fisika,Komputer Sain dan Matematika Terapan untuk memberikan solusi pada “Kejadian dan masalah yang komplek pada dunia nyata” baik dengan menggunakan simulasi juga penggunaan algoritma yang tepat.
Pemahaman fisika pada teori, experimen, dan komputasi haruslah sebanding, agar dihasilkan solusi numerik dan visualizasi /pemodelan yang tepat untuk memahami masalah Fisika. Untuk melakukan perkerjaan seperti evaluasi integral,penyelesaian persamaan differensial, penyelesaian persamaan simultans, mem-plot suatu fungsi/data, membuat pengembangan suatu seri fungsi, menemukan akar persamaan dan bekerja dengan bilangan komplek yang menjadi tujuan penerapan fisika komputasi.
Banyak perangkat lunak ataupun bahasa yang digunakan, baik MatLab, Visual Basic, Fortran,Open Source Physics (OSP), Labview, Mathematica, dan lain sebagainya digunakan untuk pemahaman dan pencarian solusi numerik dari masalah-masalah pada Fisika komputasi. Suatu yang menjadi fokus perhatian kita disini adalah penggunaan visual basicsebagai alat bantu dalam pembelajaran dan pencarian solusi Fisika komputasi.
2.3 Implementasi Komputasi Modern pada bidang Matematika
Implementasi komputasi modern di bidang matematika ada numerical analysis yaitu sebuah algoritma dipakai untuk menganalisa masalah – masalah matematika. Bidang analisis numerik sudah sudah dikembangkan berabad-abad sebelum penemuan komputer modern. Interpolasi linear sudah digunakan lebih dari 2000 tahun yang lalu. Banyak matematikawan besar dari masa lalu disibukkan oleh analisis numerik, seperti yang terlihat jelas dari nama algoritma penting seperti metode Newton,interpolasi polinomial Lagrange, eliminasi Gauss, atau metode Euler. Buku-buku besar berisi rumus dan tabel data seperti interpolasi titik dan koefisien fungsi diciptakan untuk memudahkan perhitungan tangan. Dengan menggunakan tabel ini (seringkali menampilkan perhitungan sampai 16 angka desimal atau lebih untuk beberapa fungsi), kita bisa melihat nilai-nilai untuk diisikan ke dalam rumus yang diberikan dan mencapai perkiraan numeris sangat baik untuk beberapa fungsi. Karya utama dalam bidang ini adalah penerbitan NIST yang disunting oleh Abramovich dan Stegun, sebuah buku setebal 1000 halaman lebih. Buku ini berisi banyak sekali rumus yang umum digunakan dan fungsi dan nilai-nilainya di banyak titik. Nilai f-nilai fungsi tersebut tidak lagi terlalu berguna ketika komputer tersedia, namun senarai rumus masih mungkin sangat berguna.Kalkulator mekanik juga dikembangkan sebagai alat untuk perhitungan tangan. Kalkulator ini berevolusi menjadi komputer elektronik pada tahun 1940. Kemudian ditemukan bahwa komputer juga berguna untuk tujuan administratif. Tetapi penemuan komputer juga mempengaruhi bidang analisis numerik, karena memungkinkan dilakukannya perhitungan yang lebih panjang dan rumit.
2.4 Implementasi Komputasi Modern pada bidang Biologi
Dalam implementasi komputasi modern di bidang biologi terdapat Bioinformatika, sesuai dengan asal katanya yaitu “bio” dan “informatika”, adalah gabungan antara ilmu biologi dan ilmu teknik informasi (TI). Pada umumnya, Bioinformatika didefenisikan sebagai aplikasi dari alat komputasi dan analisa untuk menangkap dan menginterpretasikan data-data biologi. Ilmu ini merupakan ilmu baru yang yang merangkup berbagai disiplin ilmu termasuk ilmu komputer, matematika dan fisika, biologi, dan ilmu kedokteran, dimana kesemuanya saling menunjang dan saling bermanfaat satu sama lainnya.
Istilah bioinformatics mulai dikemukakan pada pertengahan era 1980-an untuk mengacu pada penerapan komputer dalam biologi. Namun demikian, penerapan bidang-bidang dalam bioinformatika (seperti pembuatan basis data dan pengembangan algoritma untuk analisis sekuens biologis) sudah dilakukan sejak tahun 1960-an.
Ilmu bioinformatika lahir atas insiatif para ahli ilmu komputer berdasarkan artificial intelligence. Mereka berpikir bahwa semua gejala yang ada di alam ini bisa diuat secara artificial melalui simulasi dari gejala-gejala tersebut. Untuk mewujudkan hal ini diperlukan data-data yang yang menjadi kunci penentu tindak-tanduk gejala alam tersebut, yaitu gen yang meliputi DNA atau RNA. Bioinformatika ini penting untuk manajemen data-data dari dunia biologi dan kedokteran modern. Perangkat utama Bioinformatika adalah program software dan didukung oleh kesediaan internet.
2.5 Implementasi Komputasi Modern pada bidang Ekonomi
Terdapat Computational Economics yang mempelajari titik pertemuan antara ilmu ekonomi dan ilmu komputer mencakup komputasi keuangan, statistika, pemrograman yang di desain khusus untuk komputasi ekonomi dan pengembangan alat bantu untuk pendidikan ekonomi
2.6 Implementasi Komputasi Modern pada bidang Geologi
Pada bidang geologi teori komputasi biasanya digunakan untuk pertambangan, sebuah sistem komputer digunakan untuk menganalisa bahan-bahan mineral dan barang tambang yang terdapat di dalam tanah.
- Kesimpulan
Berdasarkan penjelasan yang dipaparkan diatas perkembangan dunia komputasi mengalami banyak peningkatan pada bidang manapun dan diharapkan dapat membantu pekerjaan manusia dan menyelesaikan setiap masalah yang di alami manusia.
- Daftar Pustaka
http://livemakefun.blogspot.com/2014/03/perkembangan-teori-komputasi-modern_16.html
http://amoekinspirasi.wordpress.com/2014/03/16/perkembangan-teori-komputasi-dan-implementasinya/
Tugas Vclass Jaringan Kompute Lanjut soal PG
[v-class Jarkom Lanjut] Jawaban Soal Pilihan Ganda :
1. Service yang cara kerjanya mirip dengan mengirim surat adalah :
a. Connection Oriented c. Semua jawaban benar
b. Connectionless Oriented d. Semua jawaban salah
Jawaban : a. Connection Oriented
2. Nama lain untuk Statistical Time Division Multiplexing (TDM) adalah :
a. Non-Intelligent TDM c. Asynchromous TDM
b. Synchronous TDM d. Semua jawaban benar
Jawaban : b. Synchronous TDM
3. Hubungan laju transmisi data dengan lebar pita saluran transmisi adalah :
a. Laju transmisi naik jika lebar pita berkuran.
b. Laju transmisi naik jika lebar pita bertambah.
c. Laju transmisi tidak bergantung pada lebar pita.
d. Semua jawaban salah.
Jawaban : d. Semua jawaban salah.
4. Teknik encoding Bipolar-AMI dan Pseudoternary termasuk dalam teknik :
a. Multilevel Binary c. Biphase
b. NRZ d. Manchester
Jawaban : a. Multilevel Binary
5. Jika dua frame ditransmisikan secara serentak maka akan menyebabkan terjadinya tubruklan. Kejadian ini dalam jaringan dikenal dengan istilah :
a. Contention c. Crash
b. Collision d. Jabber
Jawaban : c. Crash
6. Salah satu protocol CSMA yang tidak terus menerus mendengarkan channel adalah :
a. 1-persistent c. nonpersistent
b. p-persistent d. CSMA/CD
Jawaban : d. CSMA/CD
7. Salah satu protocol yang bebas dari tubrukan adalah :
a. Bit-Map c. Carrier Sense
b. CSMA d. ALOHA
Jawaban : c. Carrier Sense
8. Selective Repeater merupakan istilah lain dari :
a. Router c. Gateway
b. Bridge d. Repeater
Jawaban : a. Router
9. Dalam pemeliharaan ring logis 802.4, frame kontrol yang bertugas untuk mengijinkan suatu stasiun untuk meninggalkan ring adalah :
a. Claim_token . Token
b. Who_follows d. Set_Successor
Jawaban : c. Token
10.Algoritma yang digunakan untuk menghindari kemacetan adalah :
a. Broadcast Routing c. Optimal Routing
b. Flow Control d. Flooding Routing
Jawaban : b. Flow Control
11.Algoritma routing yang menggunakan informasi yang dikumpulkan dari subnet secara keseluruhan agar keputusannya optimal adalah :
a. Algoritma Global c. Algoritma Terisolasi
b. Algoritma Lokal d. Algoritma Terdistribusi
Jawaban : d. Algoritma Terdistribusi
12.Keuntungan multiplexing adalah :
a. Komputer host hanya memerlukan satu I/O port untuk satu terminal
b. Komputer host hanya memerlukan satu I/O port untuk banyak terminal
c. Komputer host memerlukan banyak I/O port untuk banyak terminal
d. Komputer host memerlukan banyak I/O port untuk satu terminal
Jawaban : b. Komputer host hanya memerlukan satu I/O port untuk banyak terminal
13.Jenis kabel UTP digunakan untuk jaringan Ethernet :
a. 10Base2 c. 10BaseT
b. 10Base5 d. Semua jawaban benar
Jawaban : c. 10BaseT
14.Suatu algoritma routing yang tidak mendasarkan keputusan routingnya pada kondisi topologi dan lalulintas saat itu adalah :
a. Non adaptive c. RCC
b. Adaptive d. Hot potato
Jawaban : a. Non adaptive
15.Data/message yang belum dienkripsi disebut dengan :
a. Plaintext c. Auntext
b. Ciphertext d. Choke Packet
Jawaban : a. Plaintext
16.Algoritma Kontrol Kemacetan yang menjaga jumlah paket tetap konstan dengan menggunakan permits yang bersirkulasi dalam subnet adalah :
a. Kontrol Arus c. Pra Alokasi Buffer
b. Kontrol Isarithmic d. Choke Packet
Jawaban : c. Pra Alokasi Buffer
17.Sekumpulan aturan yang menentukan operasi unit-unit fungsional untuk mencapai komunikasi antar dua entitas yang berbeda adalah :
a. Sintaks c. Protokol
b. Timing d. Routing
Jawaban : c. Protokol
18.Algoritma yang digunakan oleh transparent bridge adalah :
a. RCC c. Flooding
b. Backward Learning d. Shortest path
Jawaban : b. Backward Learning
19.Dalam model OSI internetworking membagi lapisan network menjadi beberapa bagian, kecuali
a. Intranet sublayer c. Internet sublayer
b. Access sublayer d. Enhanchement sublayer
Jawaban : a. Intranet sublayer
20.Teknik time domain reflectometry digunakan pada standard IEEE:
a. 802.2 c. 802.4
b. 802.3 d. 802.5
Jawaban : b. 802.3
21.Suatu cara yang mempunyai kemampuan untuk menyedian privacy, authenticity, integrity dan pengamanan data adalah :
a. Enkripsi c. Deskripsi
b. Antisipasi d. Semua jawaban salah
Jawaban : a. Enkripsi
22.Tujuan adanya jaringan komputer adalah…..
a. Resource sharing c. High reability
b. Penghematan biaya d. Semua jawaban benar
Jawaban : d. Semua jawaban benar
23.Mengontrol suapaya tidak terjadi deadlock merupakan fungsi dari lapisan :
a. Network Layer c. Data link Layer
b. Session Layer d. Application Layer
Jawaban : a. Network Layer
24.Frame yang terjadi apabila suatu stasiun mentransmisikan frame pendek kejalur ring yang panjang dan bertubrukan atau dimatikan sebelum frame tersebut dikeluarkan. Frame ini disebut dengan istilah :
a. Orphan c. Pure
b. Beacon d. Semua jawaban salah
Jawaban : b. Beacon
25.Wire center digunakan pada standar :
a. 802.2 c. 802.4
b. 802.3 d. 802.5
Jawaban : b. 802.3
26.Komponen dasar model komunikasi adalah :
a. Sumber c. Media
b. Tujuan d. Semua benar
Jawaban : d. Semua benar
27.Di bawah ini termasuk Broadcast network :
a. Circuit Switching c. Satelit
b. Paket Switching d. Semi Paket Switching
Jawaban : c. Satelit
28.Paket radio termasuk golongan :
a. Broadcast c. Publik
b. Switched d. Semua benar
Jawaban : a. Broadcast
29.Di bawah ini termasuk guided media :
a. UTP c. Fiber Optik
b. Coaxial d. Semua benar
Jawaban : d. Semua benar
30.Modul transmisi yang sifatnya searah adalah :
a. Pager c. TV
b. Simpleks d. Semua benar
Jawaban : c. TV
TUGAS V-class Jaringan Komputer Lanjut – ESSAY
1. Apakah dimaksud dengan komunikasi broadband ?
2. Sebutkan keuntungan SONET !
3. Jelaskan prinsip kerja dari ATM !
4. Apakah yang dimaksud dengan DSL ?
Jawaban:
1. Komunikasi Broadband merupakan komunikasi data yang memiliki kecepatan tinggi dan juga memiliki bandwidth yang besar. Ada beberapa definisi untuk komunikasi broadband, antara lain : menurut rekomendasi ITU No. I.113, “Komunikasi broadband didefinisikan sebagai komunikasi dengan kecepatan transmisi 1,5 Mbps hingga 2,0 Mbps.”. sedangkan menurut FCC di amerika, “ komunikasi broadband dicirikan dengan suatu komunikasi yang memiliki kecepatan simetri (up-stream dan down-stream) minimal 200 kbps. Maka dari itu komunikasi brodband sering disebut juga dengan komunikasi masa depan. Broadband itu sendiri menggunakan beberapa teknologi yang dibedakan sebagai berikut :
a. Digitas Subscriber Line (DSL).
b. Modem Kabel.
c. Broadband Wireless Access (WiFi dan WiMAX).
d. Satelit.
e. Selular.
2. Keuntungan SONET (Synchronous Optical Networking) :
a. Dapat memberikan fungsionalitas yang bagus baik pada jaringan kecil, medium, maupun besar.
b. Collector rings menyediakan interface ke seluruh aplikasi, termasuk local office, PABX, access multiplexer, BTS, dan terminal ATM.
c. Manejemen bandwith berfungsi untuk proses routing, dan manajemen trafik.
d. Jaringan backbone berfungsi menyediakan konektifitas untuk jaringan jarak jauh.
e. Memiliki fitur redudansi yang mirip dengan FDDI.
3. Prinsip kerja ATM (Automatic Teller Machine) :
a. Pada ATM, informasi dikirim dalam blok data dengan panjang tetap yang disebut sel. Sel merupakan unit dari switching dan transmisi.
b. Untuk mendukung layanan dengan rate yang beragam, maka pada selang waktu tertentu dapat dikirimkan sel dengan jumlah sesuai dengan rate-nya.
c. Sebuah sel terdiri atas information field yang berisi informasi pemakai dan sebuah header.
d. Informasi field dikirim dengan transparan oleh jaringan ATM dan tak ada proses yang dikenakan padanya oleh jaringan.
e. Urutan sel dijaga oleh jaringan, dan sel diterima dengan urutan yang sama seperti pada waktu kirim.
f. Header berisi label yang melambangkan informasi jaringan seperti addressing dan routing.
g. Dikatakan merupakan kombinasi dari konsep circuit dan packet switching, karena ATM memakai konsep connection oriented dan mengggunakan konsep paket berupa sel.
h. Setiap hubungan mempunyai kapasitas transfer (bandwidth) yang ditentukan sesuai dengan permintaan pemakai, asalkan kapasitas atau resource-nya tersedia.
i. Dengan resource yang sama, jaringan mampu atau dapat membawa beban yang lebih banyak karena jaringan mempunyai kemampuan statistical multiplexing.
4. DSL (Digital Subcriber Line) merupakan atu set teknologi yang menyediakan penghantar data digital melewati kabel yang digunakan dalam jarak dekat dari jaringan telepon setempat, biasanya kecepatan downolad dari DSL berkisar dari 128 kbit/d sampai 24.000 kb/d tergantung dari teknologi DSL tersebut. Kecepatan upload lebih rendah dari download untuk ADSL dan sama cepat untuk SDSL.
contoh teknologi DSL (kadang disebut dengan xDSL) termasuk:
a. High-bit-rate Digital Subscriber Line (HDSL)
b. Symmetric Digital Subscriber Line (SDSL)
c. Asymmetric Digital Subscriber Line (ADSL)
d. Rate-Adaptive Digital Subscriber Line (RADSL)
e. Very-high-bit-rate Digital Subscriber Line (VDSL)
f. Very-high-bit-rate Digital Subscriber Line 2 (VDSL2)
g. Symmetric High-speed Digital Subscriber Line (G.SHDSL)
Pengantar Bisnis Pertemuan 4
Tugas Softskill Minggu 4
Pada minggu keempat kami berhasil menyelesaikan target dengan total download 500 yaitu aplikasi pembelajaran kimia kelas 10
Aplikasi ini banyak di download
Karena ukuran yang kecil, terlebih lagi sebagian besar yang mendownload anak sekolah. Dan mereka pun meminta supaya kami mengembangkan aplikasi untuk kelas 11 dan kelas 12.
Ini adalah screenshot hasil pencapaian kami

Pengantar Bisnis pertemuan 3
Tugas Softskill Minggu 3
Pada minggu ketiga kami mengupload pada server khusus untuk develope aplikasi android. Di karenakan pada mediafire banyak yang kurang yakin takut di anggap hoax..

http://www.droidbin.com/p189gpuajp1snp190am2is2s1rrs3

http://www.droidbin.com/p18af8iapnbb83pj7eo10jmqd73

http://www.droidbin.com/p18afakgsg1mbk2k4urc17kb7j73
ini adalah hasil pencapaian setelah di unggah pada droidbin.com

Pengantar Bisnis TI pertemuan 2
pada pertemuan hari ini kami mempresentasikan hasil perkembangan tugas yang kami lakukan
namun perkembangan yang di dapat masih sama seperti minggu lalu
dan kita mengerjakan tugas dengan giat agar target dapat tercapai dengan mempromosikan kepada orang-orang di berbagai jejaring sosial
